基础设置
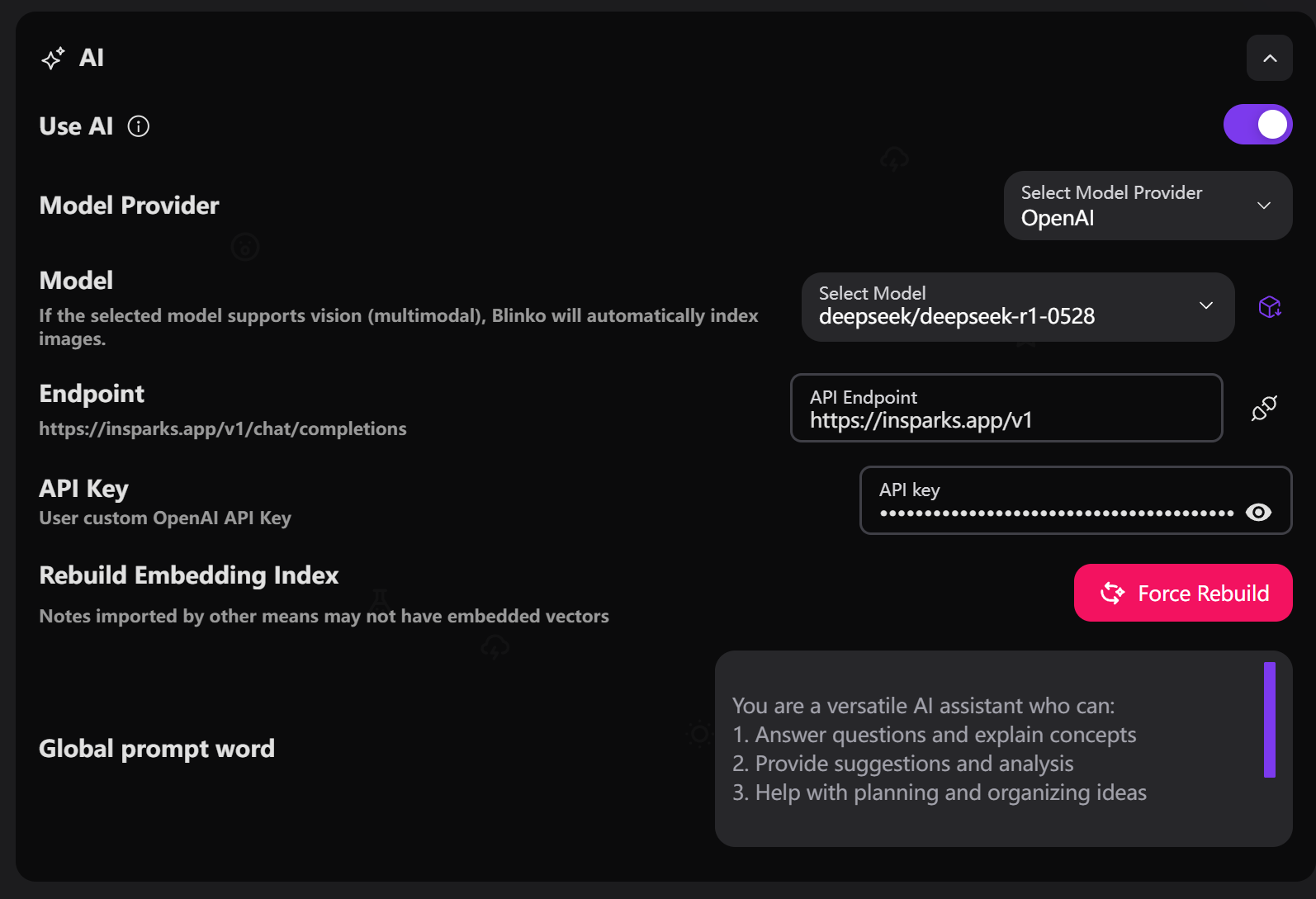
1. 启用AI
1. 启用AI
- 在设置中找到”使用AI”开关
- 将其切换到启用状态(紫色)
2. 选择模型提供商
2. 选择模型提供商
支持的模型提供商:
- OpenAI: 官方模型和API
- AzureOpenAI: 微软Azure平台
- Anthropic: Claude系列模型
- DeepSeek: DeepSeek系列模型
- Gemini: Google Gemini模型
- Grok: xAI Grok模型
- Ollama: 本地部署模型
- OpenRouter: 多模型聚合平台
3. 选择AI模型
3. 选择AI模型
- 根据提供商选择对应的AI模型
- 推荐模型:
- OpenAI: gpt-4o, gpt-4o-mini
- Anthropic: claude-3-5-sonnet
- DeepSeek: deepseek-chat
4. 配置API密钥
4. 配置API密钥
- 在”API密钥”输入框中输入密钥
- 确保密钥有效且具有必要权限
- 不同提供商需要不同的密钥格式
5. 设置API端点(可选)
5. 设置API端点(可选)
- 自定义API端点地址
- 用于代理或自部署服务
- 留空则使用默认端点
嵌入设置
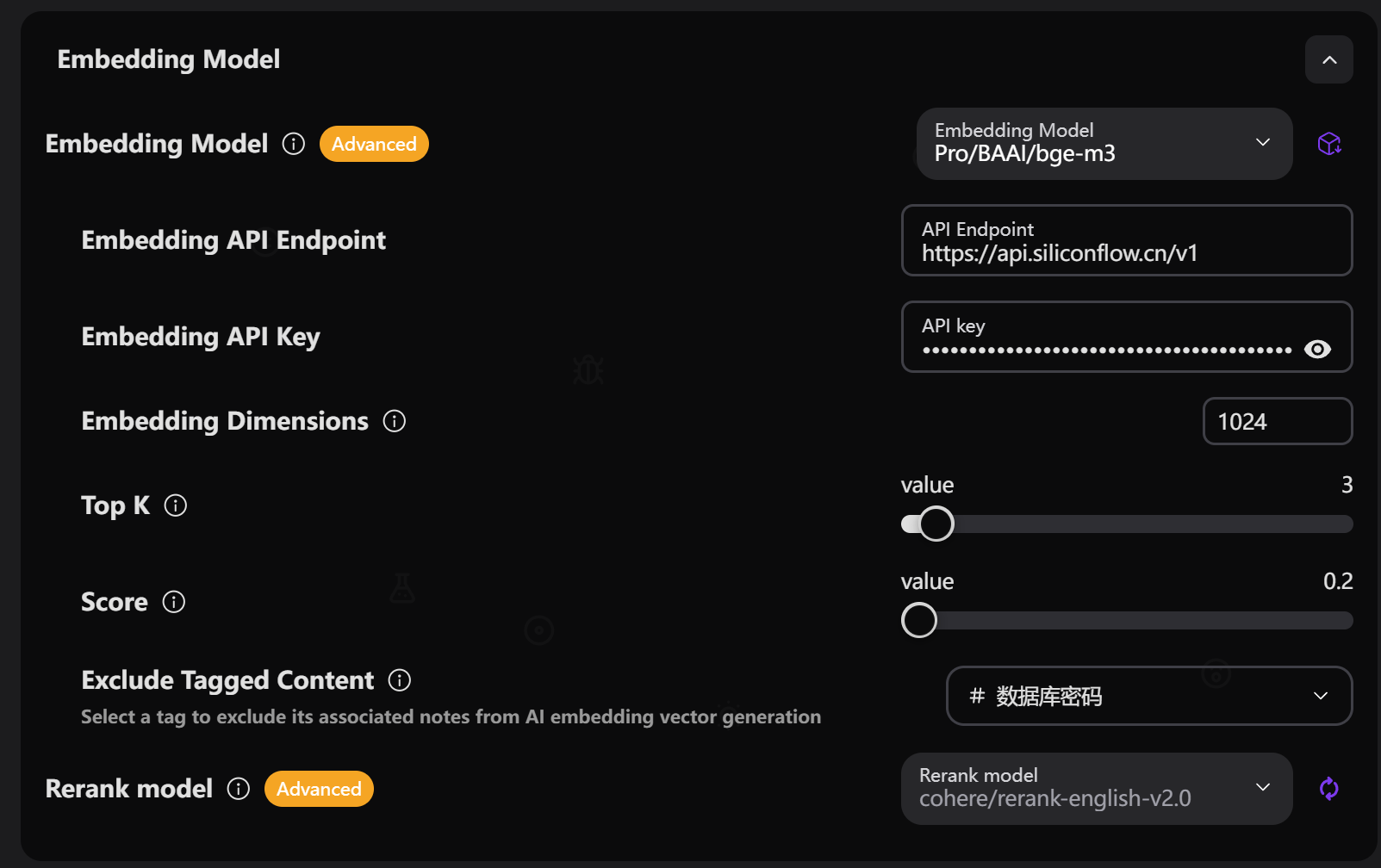
嵌入模型
嵌入模型
- 选择用于生成文本嵌入的模型
- 支持独立的嵌入API密钥和端点
- 推荐模型:
- OpenAI: text-embedding-3-small, text-embedding-3-large
- Voyage: voyage-3-lite, voyage-large-2
重建嵌入索引
重建嵌入索引
- 重建:增量更新嵌入索引
- 强制重建:完全重新生成所有嵌入
- 更换嵌入模型后需要重建索引
嵌入维度
嵌入维度
- 设置嵌入向量的维度大小
- 自动检测常见模型的维度
- 自定义模型需手动设置
搜索优化设置
[需要搜索设置截图]Embedding Top K
Embedding Top K
- 嵌入搜索返回的最相关片段数量
- 范围:1-20(推荐:3-5)
- 更高的值包括更多上下文
Embedding Score
Embedding Score
- 嵌入搜索的最低相似度分数阈值
- 范围:0.0-1.0(推荐:0.4-0.7)
- 更高的值确保更相关的匹配
重排模型
重排模型
- 使用大语言模型进行结果重排序
- 提高搜索结果的相关性和准确性
- 注意:目前需要使用大语言模型,AI SDK框架暂未支持专用重排模型
重排设置
重排设置
- 重排 Top K:重排序处理的结果数量
- 重排分数:重排后的最低分数阈值
- 使用嵌入端点:是否使用独立的嵌入API端点
代理设置
HTTP代理
HTTP代理
- 启用HTTP代理访问AI服务
- 配置代理主机、端口和认证信息
- 适用于网络受限环境
测试连接
连接测试
连接测试
- 点击”测试连接”验证配置
- 检查API密钥和端点的有效性
- 确保网络连接正常